Step.4 設計・開発・テストの管理
設計・開発の実施計画が完成したら、いよいよ設計・開発の作業が始まります。PJMOは、事業者との定例会議で進捗状況や課題等を確認していくことになりますが、報告を聞いているだけでは、後々トラブルを招きかねない問題を早期に発見することはできません。
ここでは、問題を早期に発見・対応して品質の良い情報システムを構築していくための知識やノウハウについて説明していきます。
設計内容を確認・調整する
【標準ガイドライン関連箇所:第3編第7章第5節】
事業者は、設計作業において、要件定義の内容を具体化・詳細化し、設計書を作成します。設計書は、専門的な内容も多く、分量も非常に多くなります。全ての設計書を念入りに確認する時間があればよいですが、なかなかそんな時間は取れないでしょう。しかし、ポイントを押さえて設計書を確認して、必要な指摘や調整を行えば、後々のトラブルを避けて円滑にプロジェクトを運営していくことができます。
基本設計の内容を確実にレビューする
設計書に書かれていることと本来の要件との間にかい離がある場合、その事に気づくのが遅れるほど、修正に要するお金と労力が増えていきます。設計書は、要点を押さえ対象を絞る等の工夫をしながら必ず内容をレビューしましょう。
設計書のレビューは、基本的に「基本設計」で作られた成果物を対象とします。これは、発注者側で用意した要件定義書と事業者の作成する成果物の界面になるからです。基本設計以降は、基本設計に基づいて詳細設計や実装等が行われるため、それらの整合性を確認するのは基本的に事業者の責任範囲となります。レビューを行う際の観点を以下に示します。
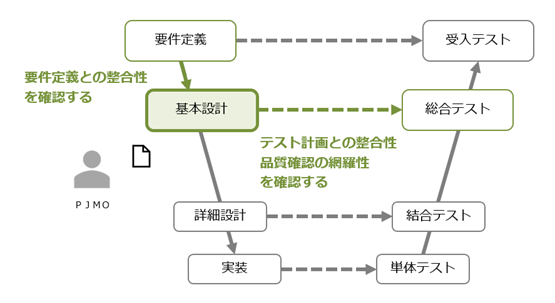
レビューの観点
-
設計書と要件定義書との整合性、設計書間での整合性が取れているかを確認する。
-
テスト計画での確認内容と設計書の内容の整合性が取れているか、要件定義で示されている内容がテスト計画で網羅されているかを確認する。
- 図7-13
設計レビューの観点イメージ
- 参考7-5
忘れがちな突合作業
他の情報システムとのデータ連携には細心の注意を払う
情報システムの多くは、他の情報システムとデータ連携を行います。そして、このデータ連携では、高い確率で様々な問題が発生します。以下に、他の情報システムとの連携における代表的な問題を示します。
データ連携における代表的な問題
-
処理タイミングにずれがあり、データが必要な時点までにデータ連携が間に合わない。
-
項目、内容、定義にずれがあり、データが連携されても双方でデータ項目に対する認識が異なる。
-
過去データの扱いに差異があり、最新情報だけが連携されて過去データが連携されない場合がある。履歴データの保持期間が双方で異なる、等。
-
データ連携は可能であるが、大量データのやり取りに許容範囲を超える処理時間がかかる。
これらの問題を起こさないためには、まずは、他の情報システム側の担当者等との協力体制を築くことが第一です。それを踏まえた上で、次の点に注意して設計・開発を進めていきましょう。
データ連携での問題発生を防ぐために
-
他の情報システムの担当者や事業者と定期的なコミュニケーションが図れるように、計画段階で役割を明確化し、情報共有や調整の仕方を定めておく。
-
データ連携仕様やインタフェース設計については、早期に作成し、関係者と共有し、十分な相互レビューを経て合意する。また、なおこれらの仕様を確定する時期については、重要なマイルストーンとしてスケジュールに組み込み、入念に進捗管理を行う。
-
既に他の情報システムでデータ連携仕様が決定している場合は、その情報を早い段階で受領する。
-
他の情報システムとのテストは、早いうちから段階を踏んで実施する。例えば、データのバリエーション試験は、結合テストの段階で他の情報システムからデータを受領して行う等、工夫する。 また、テストを実施するためには、基本的に本番環境とは別のテスト環境が必要となるので、その準備や調整を早期から行う。
品質管理の考え方を理解する
【標準ガイドライン関連箇所:第3編第7章第5節】
PJMOは、設計が完了した後は、テストを通じて品質を確認していくことがメインになっていきます。テスト工程に応じた品質確認の知識やノウハウは、以降で示していきますが、ここでは、テスト工程全体を通じて大切な品質管理のポイントを説明していきます。
見えない品質を見える状態にする
ソフトウェアはハードウェアと違って実態が見えないため、直接品質を計測することが困難です。一般的には、ソフトウェアの利用時の品質はソフトウェア製品の品質(内部特徴、外部特徴)に依存し、そのソフトウェア製品の品質はソフトウェアを作るプロセスの品質に依存すると言われています(下図参照)。そのため、ソフトウェアの品質管理では、改善を継続し高品質なプロセスを目指すことが重要です。
- 図7-14
それでは、高品質なプロセスをどのように作っていけば良いのでしょうか。
高品質なプロセスはPDCA等のフレームワークを活用した上で、持続的に実施する日々のプロセス改善により確立されるものです。
しかし、やみくもにプロセス改善を実施しても効果が薄く、実施している作業の作業プロセスの問題や課題を把握し、それらに対して対処する必要があります。
問題や課題の把握方法・分析方法には様々な方法があります。ここでは信頼度成長曲線を例として挙げますが、あくまでも問題や課題を見つけるための一例です。信頼度成長曲線を用いれば「品質に問題がない」と言えるわけではないことに注意してください。
信頼度成長曲線は、バグの収束傾向を見極めるものですが、同時に進捗と品質も見ることで、プロセスも評価します。下図の青の実線は「テストケース残数」、青の点線は「テストケース見込残数」、オレンジの実線は「障害累計件数」、オレンジの点線は「障害見込件数」、緑の実線は「障害解決累計件数」です。
図7-15の青い実線を見ると、きれいな逆S字カーブでテストケースを順調に消化していたことがわかります。
オレンジの点線(障害見込件数)は、テスト実施前に正確に見積ることは難しいでしょう。一般的には、単体テストや結合テストではシステム全体での障害摘出(件数/KStep)を過去の経験等から設定し、テスト実施対象のステップ数と掛け合わせることで求めることが多いです。一方、総合テストではテストシナリオ単位で個別の障害見込件数を予測することが難しくなるので、システムの全体規模(KStep)に対して障害見込件数を計算した上で、最終的な収束見込を管理することもあります。
なお、テスト項目密度や不良密度といった指標値に対して目標水準を設定する事業者もいますが、PJMOはそれらの目標水準が信頼できる根拠に基づいて設定されているか注意する必要があります(Step4-3.B.「テスト項目密度と不良密度の確認ポイント」を参照)。
例えば、目標水準の算出元となった過去事例等とプロジェクトに十分な類似性(プログラミング言語、開発方式、開発規模、サービスの内容等)が認められないと信頼できる水準とは言えません。
また、仮に十分な根拠があったとしても、水準の範囲内に収まっていれば品質に問題がないと断定するのは誤った考え方で、これらの指標値は水準の中に収まらない対象に着目し、プロセス上の問題を洗い出すために利用するものです。
適切な根拠となっているか見極めた上で、洗い出した問題を解決しプロセス改善に役立てていきましょう。
- 図7-15
信頼度成長曲線のイメージ
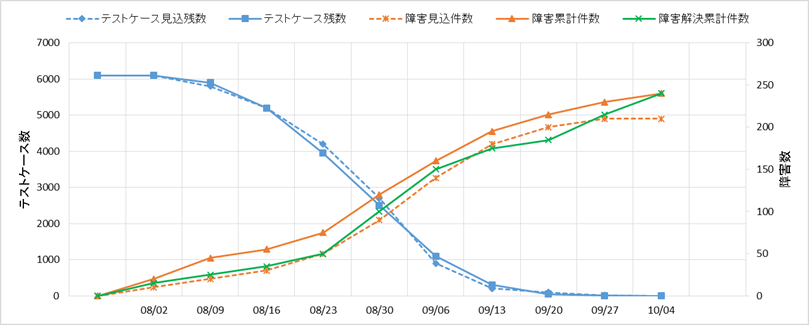
障害累計件数の実績が、計画に対して下振れしていた場合に、考えられることは2つあります。1つは、システムの品質が想定より良いという好ましい状態、もう1つは、テストの実施方法が甘く、十分に障害を摘出できていない状態です。このように両方の解釈が考えられるため、テストの途中段階で計画と実績のかい離に一喜一憂することにはあまり意味がありません。ただし、計画に対して実績が大きくかい離している場合は、テストの実施方法が妥当であるかもう一度検討してみてください。
特に重要なのは、最終的にテストを全件消化したときの障害摘出件数が十分か、そして摘出した障害に対して確実に対応が出来ているかどうかです。信頼度成長曲線では、システム全体での障害件数を合計していますが、一部の機能に障害が残っていても見過ごしてしまう危険性があります。機能単位でどのような障害が発生しているかを評価する方法については、後述します。
- 図7-16
信頼度成長曲線(悪い例)
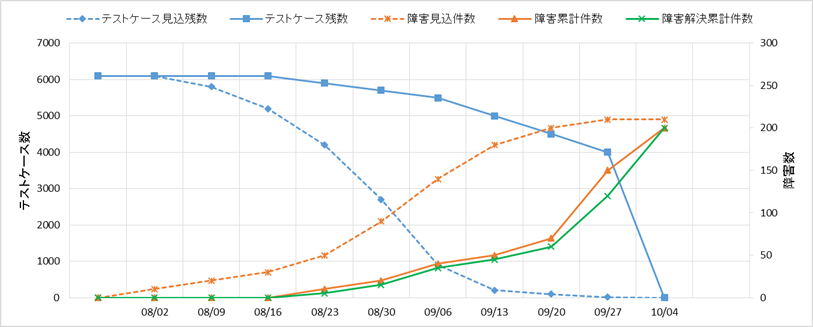
図7-16は、最後1週間でテスト消化を駆け込んだように見え、手間が掛かる複雑な条件や異常系テストが不十分な可能性があります。
こういった場合は要注意であると知っておく必要があります。
信頼度成長曲線を見るポイントは、①テストケースがムラなく消化され、②不良が滞留せずに順調に消化され、③終盤には障害累計曲線が寝ている(摘出障害がほとんど増加しない)ことです。
繰り返しになりますが、高品質なプロセスは持続的に実施する日々のプロセス改善により確立されます。信頼度成長曲線はあくまでも実施している作業の作業プロセスの問題や課題を把握する一つの手法に過ぎず、これをもとにプロセス改善を実施できるかが重要となります。
障害原因について、納得ゆくまで説明してもらう
発見した障害については、対応状況を確実に追いかけましょう。
対応完了として一度クローズした障害がまた再発することもあるので、障害については一回きりの報告書ではなく、図7-17のような継続管理できる一覧表形式とすることが良いでしょう。この一覧表では、発生日、障害件名、障害内容等に続けて、対処内容、原因(真因)、対応状況等が明確に分かるように記述しています。
- 図7-17
障害管理一覧表の例(イメージ)
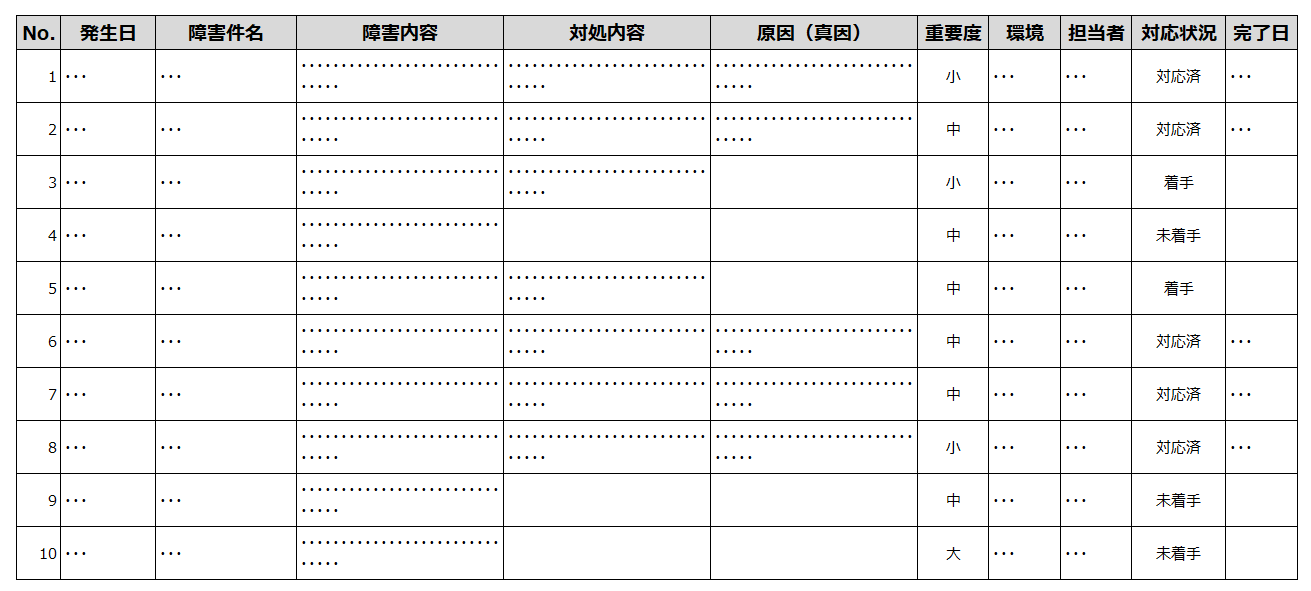
「障害原因」については、表層の理由だけでなく、深層の原因(真因)にまで深掘りして調査することが重要です。深掘りしていった結果、アプリケーションの不具合だと思っていた事象が、OSやDB、ミドルウェア、あるいはハードウェア等、異なる領域へ広がっていくことはよくあることです。事業者をまたいで調査することも多く発生しますので、発注者側が対応作業をコントロールし、このような横断調査が円滑に進むように調整することも重要です。
また、必要に応じて、PJMOの職員自身がハードウェアやミドルウェアの製品供給元の会社等から直接に話を聞くことも有益です。障害等の発生原因についてより深い理解を得ることができますし、対応策についても専門的観点から助言を受けることができます。
単体テスト・結合テストの品質を評価する
【標準ガイドライン関連箇所:第3編第7章第5節】
単体テストの留意点
単体テストは実装(=コーディング)と一体的に行われるのが実態です。
テスト管理では、過負荷とならないようにマネジメントに留意します。単体テストは開発者が自ら試行錯誤しながら実施するので、不具合件数は過少報告されがちです。その結果、管理ポイントはむしろ進捗管理であり、品質面ではソース規模とテストケース管理です。不具合報告を正直にあげることには勇気がいるので、くれぐれもそれを非難したりすることのないようにしましょう。
テスト評価では、基本的に単体テストが委託先の責任領域であるため、発注者側が単体テストに対して評価できることは限られています。それでも丸投げとならないよう、①静的解析ツール、②ソース規模測定ツール、③カバレッジ測定ツールの結果を、メソッドやモジュール単位ではなく、次の結合テストの単位である画面、バッチごとにグルーピングして評価します。また、定量評価の「ゼロ」と「100」も危険です。「バグゼロ」は高品質ではなく、テスト不十分と考えるべきです。さらにカバレッジ100%も、通常はソースの中に起こり得ないような異常処理や例外処理などが必ず含まれているので、一旦は疑ってツールの出力結果などエビデンスの提示を求めることをお勧めします。ここで必要なことは、「100%やりました」という字句をそのまま信じることなく、ツールが出力した結果をエビデンスとして確認することです。
単体テストの品質までは、発注者側はチェックできない
単体テストはそもそも、発注者側にとっては把握する必要はありません。それは事業者が掌握すべき事項であり、発注者が認識するのは結合テスト以降が妥当です。発注者側で把握する必要がない理由は、単体テストはプログラマ個人がテストし、かつクラスやメソッド単位で技術的視点に終始しているからです。
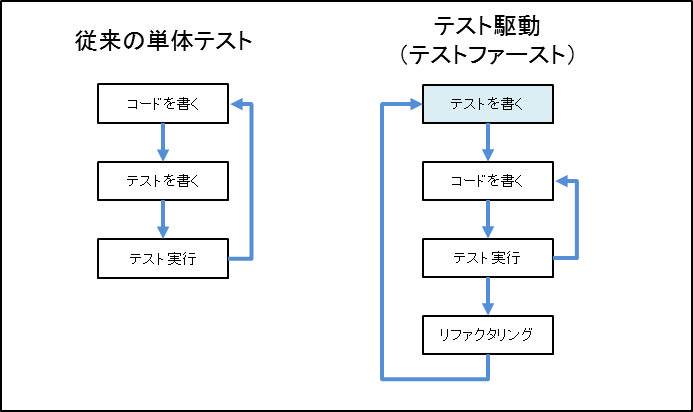
さらにアジャイル開発でベストプラクティスとされているテスト駆動開発(テストファースト)では、図7-18のようにテストしながらコードを作りこむため、そもそもバグをカウントすること自体が難しくなります。
- 図7-18
テスト駆動開発(テストファースト)のプロセス
コードカバレッジの確認ポイント
単体テストでは、コードカバレッジの計測が重要視されます。コードカバレッジとは、命令・分岐・条件の網羅率を指す考え方です。ただし、絶対に100%とする必要は無く、システムの特性と費用対効果を踏まえて、目標カバレッジを設定しましょう。
結合テストの留意点
結合テストは事業者が主体となって実施する工程ですが、発注者もテスト計画、テスト管理状況、テスト結果等については積極的に確認しましょう。結合テストは、画面単位、ジョブ単位で機能ごとに結合させてテストします。特にシステム改修の場合は、いきなり画面やジョブに組み込んで「単体テスト」と称する場合があるので、本来やるべき単体テストを飛ばしていないか注意します。一般論として、結合テストの粒度は5~20個ぐらいの単体モジュールの結合となります。それ以上の単体モジュールを結合テストで一気にテストしようとすると品質評価が難しくなるので、全体規模が大きい場合には次の総合テストの前に「結合テスト2」としてもう一段テスト工程を区切ると良いです。
テスト内容を設計する中では、①正常系だけでなく、②エラー・異常系、③例外的、縮退などの特殊パターンまで含めるようにします。経験上、多くのバグは②エラー・異常系の周辺に偏在しているものです。一方、③例外的、縮退などの特殊パターンはテストが面倒なので、後回しになったり抜け落ちたりしがちなので注視するようにします。また、全ての組み合わせをテストするのではなく、効率的なケース設計を推奨するようにします。これはテスト工数を削減するためではなく、テスト結果の見落としを防ぐことが目的です。結合テストでは、データベースやファイルへの入出力、ログ出力、暗号化/復号化、同時アクセス・排他制御など、業務目線だけでなくシステム目線の観点についても網羅されているかチェックします。これについてはチェックリストとして整備しておくのが望ましいです。
テスト実施では、始めに結合したモジュール疎通テストを実施後、コンポーネント間のインタフェースを念入りにテストし、その後、①正常系、②異常系、③特殊パターンの順にテストケースを消化します。
テスト管理では、進捗と品質の両面が重要となる局面なので、信頼度成長曲線で管理することが望ましいです。進捗面では、特に立ち上がり時のケース消化状況と停滞した時の原因を丁寧にヒアリングします。品質面では、「どこに」不具合が偏在しているかと、その箇所に品質強化テストを課す必要があるかを見極めます。「問題なし」というのが一番心配なので、あらかじめ「ワースト順に全体の1割に該当するモジュールは品質強化テストを課す」というようなルールを決めておくと良いでしょう。
結合テストで単体テストと同じことをしてはいけない
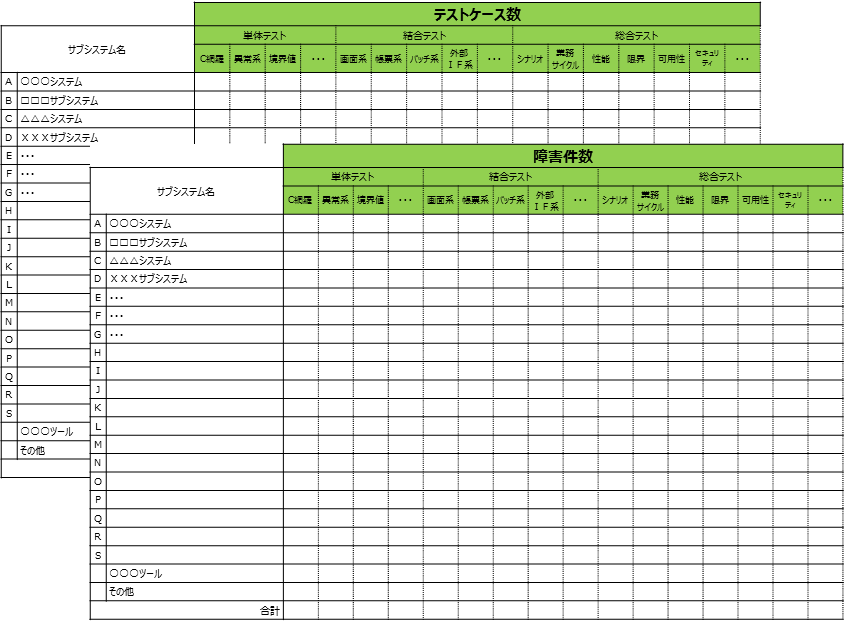
単体テストは結合テストの括りで整理し、両方のテスト結果を一覧で比較します。 テストケース数と障害件数のそれぞれについて、単体テストから結合テストへの推移で品質を判断するのがわかりやすいです。図7-19で示すテスト品質メトリクス一覧表はテストの種類ごとのテストケース数を示しており、同様のフォーマットで障害件数も記録します。縦軸(サブシステム単位、機能単位)の粒度を揃えることで、横軸の単体テスト、結合テスト、総合テストと推移する過程でどこのテストケース数が甘いか、どのレベルで障害が多発しているかがわかります。またこれによってテスト項目密度、障害摘出率をサブシステム間で比較することもできます。
- 図7-19
テスト品質メトリクス一覧表(テストケース数、障害件数)
テスト項目密度と不良密度の確認ポイント
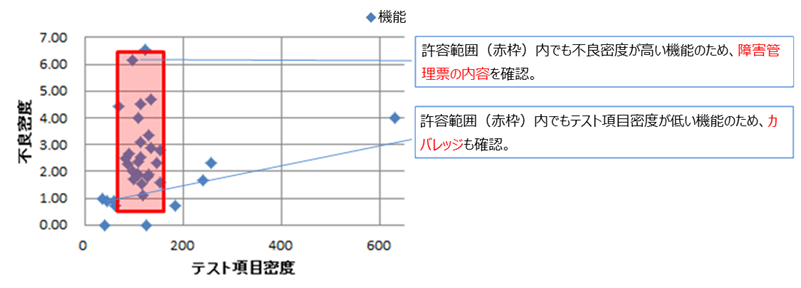
テストの実施状況を機能単位等で詳細に把握するには、それぞれの機能に対するテスト項目密度と不良密度を見ます。図7-20のように、散布図の形でプロットすると、機能毎のテスト状況を可視化することができます。
テスト項目密度と不良密度の両方が許容範囲に収まっていれば問題ありませんが、テスト項目密度が低いもの、不良密度が高いものには注意を払います。図7-20の太枠の中に収まっていれば合格です。色のついていない箇所もあまり問題視しませんが、吹き出しのある箇所は念入りにチェックさせる必要があります。ただし、考え方としては、許容範囲から外れたら「不合格」というのではなく、許容範囲に収まっている分には「敢えて説明を求めない」とするのが良いです。例えば、「テスト項目密度・不良密度が下限値を下回っているのは1KLOC未満だから」とか「不良密度が高かったのでテストケースを追加した結果テスト項目密度も高くなった」とか説明ができれば問題ありません。
- 図7-20
テスト密度と不良密度でチェックすべき箇所
なお、不良密度には真逆の解釈が成り立ちます。1つはこの値が低いことを高品質とする見方です。もう1つはこの値が低いのはバグが摘出しきれずに潜伏したままだとする見方です。このどちらかの立場から見るかはツールやテスト手法、要員のスキルや組織の成熟度などから総合的に判断するしかないため、上記のようなプロット図を指し示しながら、開発事業者のプロジェクトマネージャや品質管理者からヒアリングするしかありません。
事業者の品質指標は(当然ですが)許容範囲の幅を大きめにしていると考えるべきです。上限値と下限値は、中央値を設定しておおむねそれの±20~25%くらいが適当と考えられますが、全体の25~75パーセンタイルに収まるように調整しても問題ありません。テスト項目密度、不良密度とも、単体テストが最も大きく、テスト工程が進むにつれて指標値は小さくなります。
不良密度については、後工程になるほど小さくなります。単体テスト→結合テスト、結合テスト→総合テストと推移する中で、それぞれ4分の1から5分の1くらいになることが目安の水準といえるでしょう。
最後に重要な点を強調しますが、このような品質管理の指標自体はあくまで目安です。新規構築時と機能改修時で参考とする指標値は5~10倍ほど変化することもあります。また、機能改修の場合の母体規模をどのように考えるかは、それぞれのシステム特性もあって一概に言えません。
一番重要なことは、このような指標を発注者自身も確認しながら、気づいた点については事業者に確認し、双方で品質を高めていくという活動を継続することです。不具合件数や不良密度といった定量評価で終わらず、具体的にどういう不具合内容で、その原因は何かを追求します。また、見つかった不具合については、同種の誤りがないか、得られた知見の横展開をどのように行ったかまで、根掘り葉掘り聞いていきます。
できれば、週1回程度のテスト状況報告会議を行い、そこで1週間分の不具合管理一覧表を提出してもらい、その内容について逐次説明を聞くようなやり方が良いでしょう。不具合の内容について発注者側が質問することによって、事業者のプロジェクトマネージャはそれを説明できるように配下のメンバーに質問することとなり、品質改善のPDCAが回り出します。発注者側は、決して「物わかりがいい」ふりをする必要はありません。分からないことは、どんどん質問していきましょう。
総合テストの品質を評価する
【標準ガイドライン関連箇所:第3編第7章第5節】
総合テストの留意点
総合テストは、システムごとの特性で実施すべき内容も大きく変わります。
総合テストでは、業務観点からのいろいろなシナリオに基づいて機能テストを検証しますが、これに合わせてシステムの性能や信頼性等を検証する非機能テストを行います。非機能テストについては抜け漏れが発生しがちであるため、表7-17を参考に確認すべき非機能要件がテストから漏れていないか確認してください。
- 表7-17
総合テストの観点とテスト例
- 注記
パフォーマンステストとは、負荷のかかっていない通常状態で、画面等のレスポンスタイムと、バッチ処理等のスループットを計測するテストのこと。
-
注記
ペネトレーションテストとは、システムに対して侵入テストを試み、適正にガードされていることを確認するテストのこと。
-
注記
災害対策テストとは、大規模災害発生時の対応(マニュアル含む)が的確かを確認するテストのこと。
-
注記
インシデントレスポンスとは、インシデントが発生したときにどのようなメッセージがあがり、その時の対応(マニュアル含む)が的確かを確認するテストのこと。
-
注記
縮退テストとは、部分的なハードウェアの故障などに対して、冗長構成への切替えなどが想定どおりに機能することを確認するテストのこと。
-
注記
ラッシュテストとは、性能要件として想定している最大負荷(同時アクセス数等)に対して、システムの処理能力を確認するテストのこと。
-
注記
大容量テストとは、バッチ処理の所要時間やネットワーク性能の十分性等を確認するために想定されている最大容量のデータの送受信等を確認するテストのこと。
-
注記
ストレステストとは、性能要件として想定している最大負荷を超える負荷がかかった想定外の状況に対してシステムの挙動を確認するテストのこと。
-
注記
パフォーマンステストとは、負荷のかかっていない通常状態で、画面等のレスポンスタイムと、バッチ処理等のスループットを計測するテストのこと。
-
注記
ラッシュテストとは、性能要件として想定している最大負荷(同時アクセス数等)に対して、システムの処理能力を確認するテストのこと。
総合テストの段階はリリースまでの残り日数が少なくなっていて、単体・結合テストと違って数日の遅延が致命的になるので、特に進捗管理には注意を払います。不具合対応による遅延はやむを得ない面もありますが、テスト環境や他システムとの調整など、マネジメントレベルの抜け漏れはリカバリ不可能なことがあります。
負荷テストには十分な時間を確保する
負荷テスト(ラッシュテスト、ストレステスト、大容量テスト等)やパフォーマンステストには大抵、テストツールを使って、端末からの大量アクセスによる負荷をサーバやネットワーク等にかけた状態を作り出します。
-
注記
ファジングとは、検査対象のソフトウェア製品に「ファズ(英名:fuzz)」と呼ばれる問題を引き起こしそうなデータを大量に送り込み、その応答や挙動を監視することで脆弱性を検出する検査手法のこと。
かける負荷は、ただ大きければよいというものではありません。現実に起きうるケースに近い形となるように負荷のかけかたを計算します。例えば、実際の運用時点で小容量データが多数集中することが想定されるケースで、大容量データ×最大数の負荷をかけることは現実的でありません。ただ、ストレステストについては、このような前提が超えられた時の挙動確認が目的なので、現実に起きうるケースに沿う必要はありません。
このように負荷を事前に計算することにも時間がかかりますが、負荷テストを通すための環境を準備することにも入念な調整が必要です。例えば、本番業務で実施しているネットワーク越しに負荷テストを実施してしまうと、他の本番業務に大きく影響が出てしまいます。とはいえ、本番環境に近い環境で試験しないと意味がありません。そのため、夜間等の影響の少ない時間帯に実施したり、本番環境とほぼ同一のテスト環境を用意したりする等の工夫を行いますが、このようにテスト環境を準備して調整することには時間がかかります。
また、これらのテストは1回で終わるとは想定しないほうが良いでしょう。テストの結果、性能が十分でないことが判明した場合は、システム上で何らかのチューニングを実施した上で、再度同じテストを実施します。場合によっては、何度もチューニングとテストを繰り返すこともあるかもしれません。テスト実施にも十分な時間を確保することが必要です。
機能テストは、データのバリエーションが重要
テスト工程での検証を有意義なものとするためには、検証に用いるデータについて様々な条件を備えたものを用意する必要があります。
まずは、現在動いているシステムが存在する場合は、その本番データにできるだけ近いデータを利用することです。テストケースを考えるときには、それまで検討を重ねてきた要件定義や設計内容がベースになりますが、そもそも要件として認識されていないものが本番データに含まれている可能性があります。例えば、制度変更時の経過措置で特別に処理したデータや、システム障害や天災に起因したやむを得ない応急措置により例外的で特別なデータが存在することがあります。現行システムで使っている本番データには、このように開発者にとって想定外のデータが存在するので、本番データを使ってテストすることには大きな意味があります。ただし、本番データに含まれる機密性の高い情報は、匿名化等の処理を行うことにも留意してください。
しかし、本番データがあれば十分かというと、実は本番データだけでは万全とはいえません。本番データを使ったテストは、時間とコストがかかるので、せいぜい3~4ヶ月分のデータでしか検証できないからです。そうすると、テストに使う本番データの中には、レアケースにより発生するデータが存在していないこともありえます。また、データ移行ミス等により、本来存在するはずのない誤データが潜んでいて、想定外のシステム障害を起こすようなこともあります。
このようなことに対処するためには、本番データを使ったテストだけで安心するのではなく、それ以外にも例外的なデータが発生することを予期した上で、ブラックボックステストにおけるテストケースをしっかり設定することが重要です。
なお、テスト工程の短期間だけでは検出しにくい障害もあります。例えば、業務運用を継続する中でデータベースのテーブル容量が肥大化していき、そのテーブルを読み取る処理のレスポンスが悪化し続けるというケースが実際にありました。このようなケースを回避するためには、テスト条件を設定する際に今後のデータ量増加等を見込む等の工夫を行ってください。
発見できた障害は最大限活用する
総合テストでの障害の原因は、基本設計のような上流工程で混入したものが多いはずです。そのため、障害の内容によっては、全モジュールの総点検が必要な事態もあり得ます。障害のきっかけとなった事象がレアケースだからという理由で、パッチワークのような一時しのぎの回避策をとることは危険です。安易に蓋をしてしまったがために、本稼働後に同じ事象をきっかけとする障害が発生するというケースも残念ながら存在します。障害対応を完了としてクローズする際は、慎重に検討するようにしましょう。
回り道に思えるかもしれませんが、たまたま見つかった欠陥を氷山の一角と捉えて積極的に総点検を指示することが、結果的には近道です。
事業者に対しては、類似バグがないかという観点から横展開をしているかを確認しましょう。この横展開が形式的なものになってしまわないように、事業者がどの範囲に対してどのように対象を抽出したのかを追検証できるエビデンスを必ず残してもらいましょう。横展開は非常に手間の掛かる作業ですが、たまたま発見された障害を横展開して類似バグを撲滅することは、全てをテストするよりもはるかに効率的で現実的です。
障害管理には、横展開と深掘りの2つのアプローチがあります。総合テスト段階で障害残数が収束していない状況では既知の障害に基づいた「横展開」を優先し、障害残数がコントロール可能な数にまで落ち着いてきてから1件1件の事象を「深掘り」した方が良いです。
このように総合テスト段階で障害が発生すると、とにかく面倒に感じますが、1つも疎かにせず障害管理表と向き合って、納得いくまで事業者の説明を求めるべきです。
受入テストを実施する
【標準ガイドライン関連箇所:第3編第7章第7節】
受入テストは、他のテストと異なり、職員が主体となって行う最終段階のテストです。ここでは、受入テストに関する知識やノウハウを見ていきます。
受入テストと他のテストとの違いを理解する
「サービス・業務企画や要件定義で想定したとおりに情報システムができているか?」「構築された情報システムを用いて実際のサービス・業務を正しく実施できるか?」という観点での確認は、事業者ではできません。確認できるのは、職員だけです。これらの業務視点での確認を行うのが、受入テストです。
受入テストに当たっては、次に示す点に注意してください。
受入テストに関する注意点
-
受入テストの実施期間を十分に確保することが、非常に重要です。設計・開発工程ではいずれかの工程で遅延が発生することが多く、スケジュール調整の最終手段としてテスト工程を短縮するという方法が選択されがちです。もともと1か月間で実施することを予定していた受入テストを1週間でやることになってしまうと、受入テストで本来確認すべきことを十分に確認することができません。 あらかじめ受入テストの期間をスケジュールとして確保するとともに、それまでの工程が遅延したとしても受入テストの期間短縮を安易に受け入れないように注意してください。
-
受入テストを通過すると、基本的に本番リリースに向けた準備が完了したとみなされてしまいます。実際の業務では、正常な処理だけでなく、異常な処理(エラー)も発生しますので、その時になって対処に困らないように、正常系のテストだけでなく、異常系のテストもしっかり実施しましょう。その際、事業者が受入テストの案作成を支援することもありますが、その内容をうのみにするのではなく、業務担当者の目線で内容のチェックをしてください。
-
受入テストは、職員が主体的にテストを実施する必要があります。その職員とは、PJMOの職員だけではありません。システムを実施に利用する業務実施部門の現場担当者こそ、実業務を一番よく知っています。このような現場担当者を受入テストの実施者として組み込んで、協力を得ることが効果的です。
-
受入テストに使用したデータが不用意に本番環境に継続されると、システム障害を引き起こすことがあります。転ばぬ先の杖のつもりで本当に転ばないように気を付けましょう。
受入テストは、総合テストと同様に上流工程の成果を確認するテストです。単にテスト実施者が事業者から発注者に替わるだけで、内容面では似たようなテストとなってしまいがちです。例えば、総合テストで実施したテストケースから「主要な業務」を抜き出し、発注者がその再確認をするだけで終わらせるようなこともあります。あるいは、職員が「モンキーテスト」としてその場で思いついた操作をしてみることもありますが、それで何か意味がある(つまり不具合が見つかる)ということはめったにありません。
受入テストは本番運用直前として、できるだけ「①本番データ」、「②本番環境」、「③実際の利用者」、「④実際の運用者」でテストするべきですが、そのためには相当に周到な準備が必要となります。①本番データを使う理由は、開発事業者が想定できていないような「きれいでない」データで試すためです。②本番環境の使用は機器更改のタイミング等でないと現実的ではありませんが、検証環境でテストするよりは、クラウド環境やコンテナ技術が利用できるならそのほうがよいです。③実際の利用者と④実際の運用者でテストすることで、開発事業者が思い付きもしなかったようなケースが出てくるので、異常ではないちょっと「イレギュラーな」実際のケースを思い出しつつテストしてもらうのがよいです。
受入テストでは、プロダクトとしての品質の確からしさより、リリース後の本番準備が十分かを確認しておきます。そこでは、システムマニュアルや業務マニュアルに即してテストする「マニュアルベースドテスト」が有効です。特に、正常時だけでなくエラー・障害やインシデントが発生した時、マニュアルの記載どおりで問題ないかは確認しておきます。ここでも、「③実際の利用者」にマニュアル片手でテストしてもらい、ITの専門用語や日本語がおかしくて伝わらないことのないように確認しておきます。
受入テストについては、以下のような工夫をすることで、効率的・効果的なテストを行い、業務視点での品質を高めている事例もあります。
- 事例7-5
テストの目的と業務シナリオを明確にする
受入テストのテスト計画書を作成する
この実践ガイドブックには、別添として受入テスト計画書のひな形を示しています。
- 様式例7-2
受入テスト計画書のひな形
あくまでこのひな形は例示です。移行の内容に応じて記載内容を個別に追加、変更してください。ひな形を見ると、何をどのようなレベルで書くべきかの参考になると思います。